How I monkey patch timm models to achieve SOTA steganalysis models
Our paper “Improving EfficientNet for JPEG Steganalysis” is accepted at IH&MMSEC21! We show that certain “surgical modifications” aimed at maintaining the input resolution in EfficientNet architectures significantly boost their performance in JPEG steganalysis.
In practice, we monkey patch timm models to increase the number of layers operating on the full input resolution. Here is an example of one of the modifications we propose: the post stem insertion.
net = timm.create_model('efficientnet_b6', pretrained=True, num_classes=2)
# 🙈 patching - Post Stem insertion
net.conv_stem.stride = (1,1)
net.num_post_stem_layers = 3
net.stem_size = net.conv_stem.out_channels
net.post_stem_block = timm.models.resnet.BasicBlock
net.downsample_block = timm.models.resnet.downsample_conv
post_stem_layers = [net.post_stem_block(net.stem_size, net.stem_size,
attn_layer='se')]*net.num_post_stem_layers
post_stem_layers.extend([net.post_stem_block(net.stem_size, net.stem_size, attn_layer='se',
stride=2, downsample=net.downsample_block(net.stem_size,
net.stem_size, 1, stride=2))])
net.prost_stem = nn.Sequential(*post_stem_layers)
def forward_features(self, x):
x = self.conv_stem(x)
x = self.bn1(x)
x = self.act1(x)
x = self.prost_stem(x) # Where the magic happens
x = self.blocks(x)
x = self.conv_head(x)
x = self.bn2(x)
x = self.act2(x)
return x
net.forward_features = types.MethodType(forward_features, net)The EfficientNet layers are pertained on ImageNet, while the inserted ResNet layers (and the FC) are randomly initialized. We show in the paper that pretraining the whole architecture isn’t needed. Surprising, right?
We compare the modified EfficientNets with the vanilla nets, as well as the winner model of the ALASKA II competition (SE-ReSnet 18 with stem pooling & strides disabled) in terms of FLOPs, and Memory needed to train using a batch size of 8 (although this is not a batch size we recommend, we typically used a minimum batch size of 24).
On the ALASKA II dataset (figures below), the post-stem modification boosts the performance while keeping the computational cost and the memory requirements reasonable by increasing the number of unpooled layers in the architecture. The modified models reach state-of-the-art performance with less than 1/2 of the FLOPs of the current best model. On the BOSSBase, the post-stem modification of EfficientNet also achieves state-of-the-art performance. More details in the preprint.
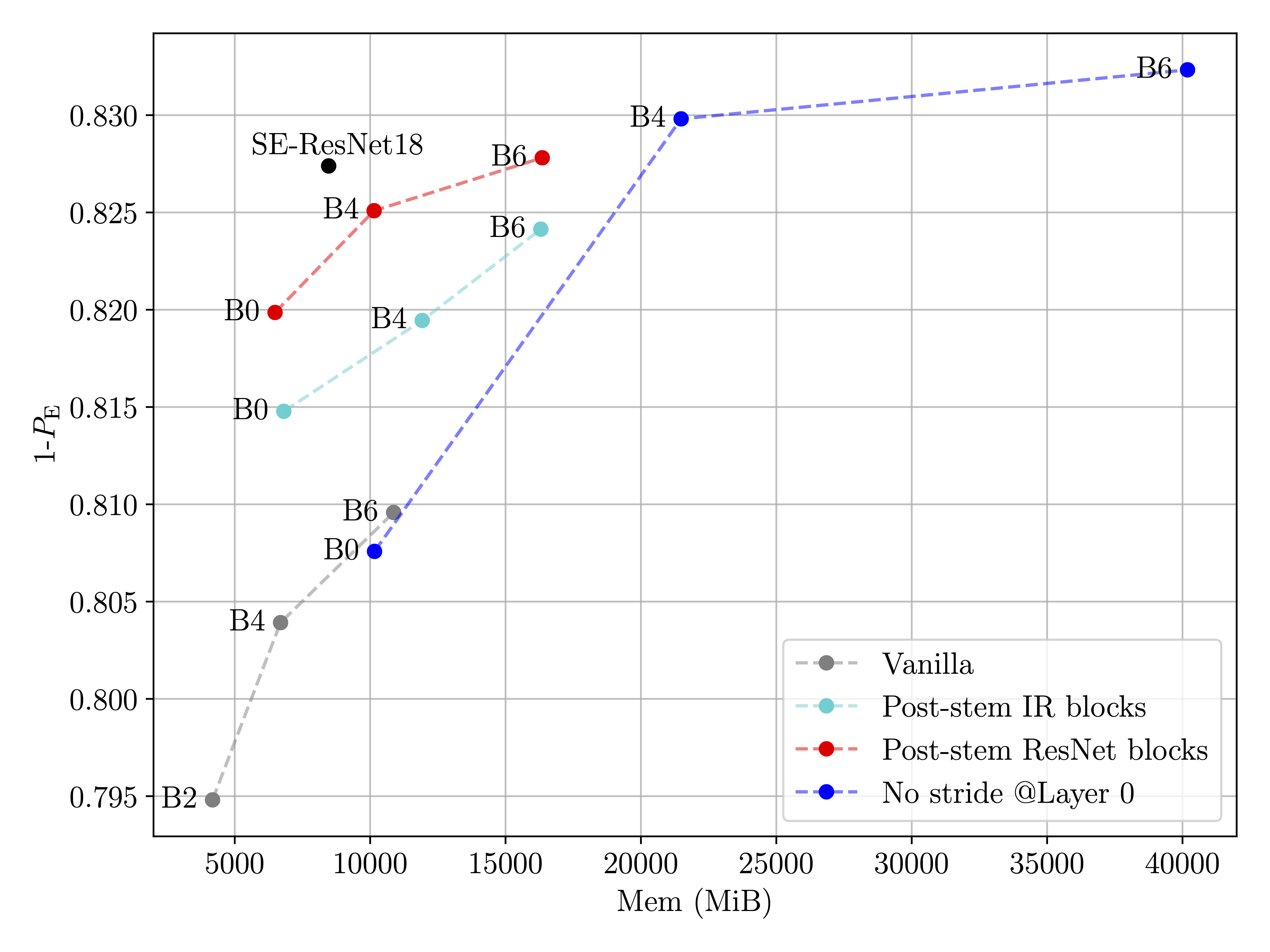
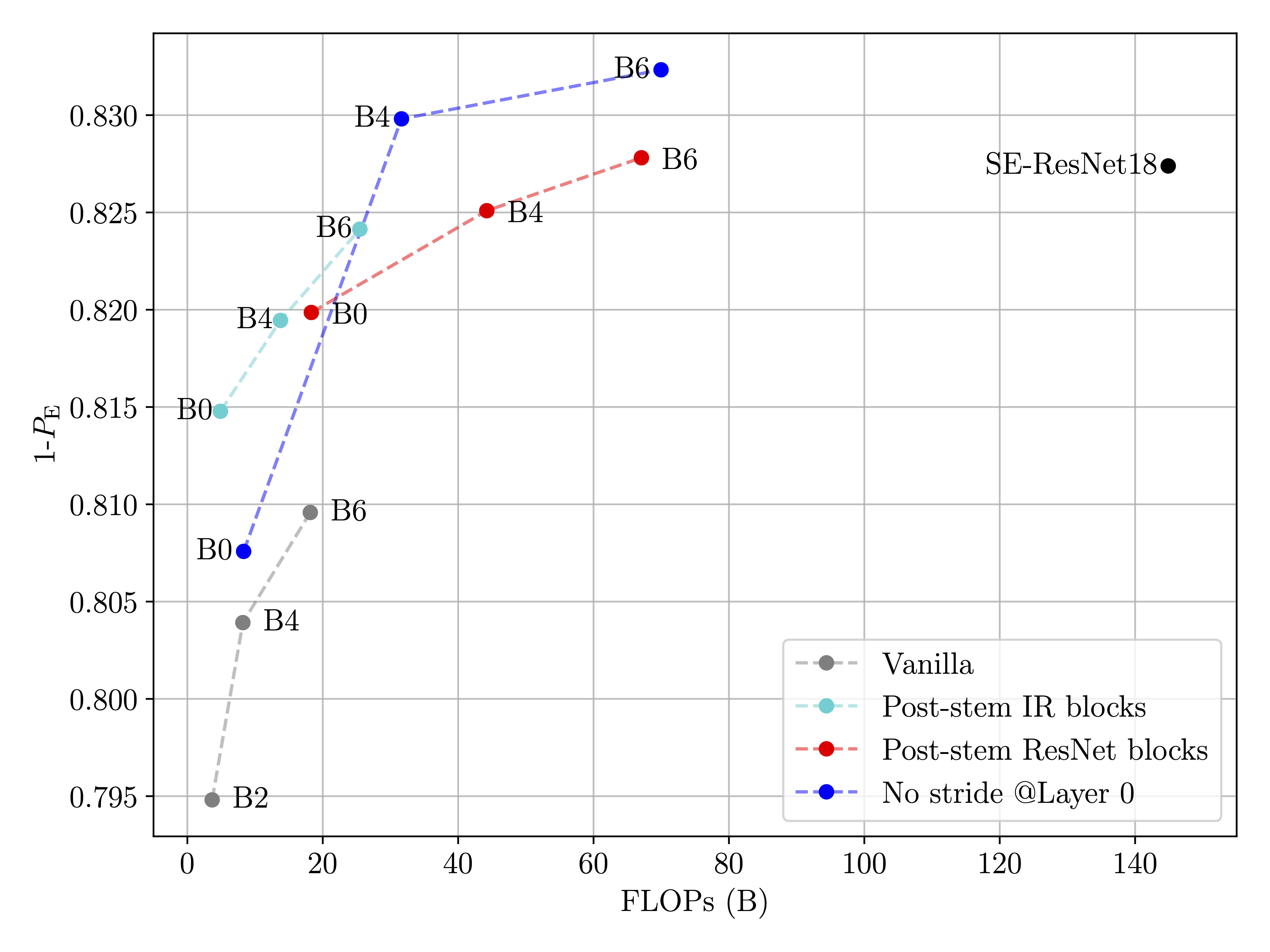
PS1. Patching objects like in the code above is not best practice, but subclassing introduced a lot of boilerplate code… I would love to hear if you have a better solution for this.
PS2. We originally used Luke’s EfficientNet-PyTorch models for the paper, then switched to timm which included ready to use code for different conv blocks.