An Intriguing Struggle of CNNs in JPEG Steganalysis and the OneHot Solution
CNNs have become the tool of choice for steganalysis because they outperform older feature-based detectors by a large margin. However, recent work points at cases where feature-based detectors perform better than CNNs due to their failure to compute simple statistics of DCT coefficients.
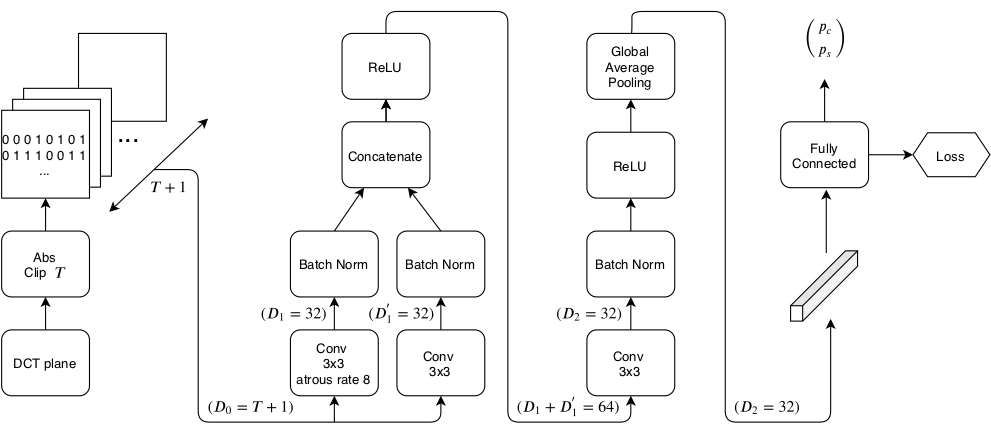
The fundamental difference between CNNs and those feature-based detectors is that CNNs operate on “spatial” domain (i.e. decompressed JPEGs) whereas feature-based detectors (JRM) operate on the DCT coefficients without converting to the “visual” domain.
In our paper published at IEEE SPL, we show that vanilla CNNs struggle to build reliable detection when fed with DCT coefficients. Which is expectable since the DCT lack locality of pixel dependencies which is necessary input property for CNNs to thrive.
We designed an architecture where CNNs are able to compute meaningful statistics directly from the DCT coefficients. To do so, we one-hot encode the DCT coefficients in the input layer, the rest is pretty much a basic CNN ;)
Read the print here.